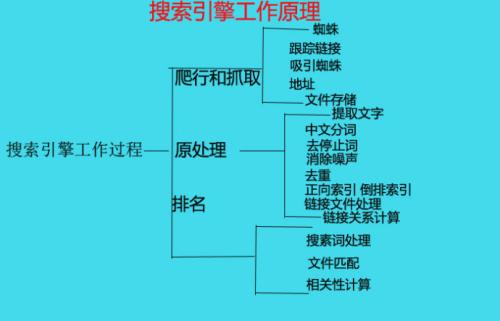
搜索引擎工作三大原理:
网页收集:什么是蜘蛛:网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动抓取互联网中网页的程序或者脚本
蜘蛛的工作方式:蜘蛛是通过链接进行爬行并抓取网页的
搜索引擎的收集机制:
根据网站的更新周期
定期定量的收集
切忌三天打鱼两天晒网
原始数据库:蜘蛛抓取的页面所要储存的位置
预处理:
提取文字:搜索引擎是以文字内容为基础的,从网页文件中去除标签、程序,提取出可以用于排名的网页文字内容
中文分词:分词,分词是搜索引擎特有的步骤,把网页中提取的文字按照词组进行划分
例:百度联盟 可拆分成 百度 联盟 百度联盟
消噪:对内容没有任何影响却大量出现的词,如:的、 地、得、啊、哦、呀、不但、而且等
去除重复页面:镜像网页,内容完全相同,网址不同,倾向原创
计算网页重要度:积分制计算,通过被指向链接计算,网页的原创性
建立索引:索引是建立关键词与网页之间的对应表,建立索引的最大好处在于可快速获取对应的数据
提取链接:根据页面中存在的链接继续抓取
检索服务:
查询词的处理
搜索词进行分词
获取排序
获取倒排索引